Проект поддержан в рамках Конкурса компании Intel по финансированию
перспективных научных исследований.
Цель проекта состояла в исследовании вычислительных схем
основных алгоритмов линейной алгебры, использованных в библиотеках научных
расчетов типа MKL, в проведении тестирования и оценке производительности таких
схем на многопроцессорных вычислительных системах кластерного типа, в разработке
требований к аппаратному обеспечению и в создании новых схем вычислений для
повышения эффективности параллельных способов решения задач.
Основные результаты выполнения проекта состоят в
следующем:
-
Разработана агрегированная информационная модель вычислительных алгоритмов,
для которой могут быть применены простые и эффективные методы анализа для
выявления наиболее адекватных способов распараллеливания;
-
Проанализирована возможности эффективной организации вычислений с
использованием архитектурных особенностей современных процессоров производства
корпорации Интел; при проведении экспериментов были разработаны программы для
задачи матричного умножения, которые выполняются быстрее не менее чем на 75%
по сравнению с соответствующей процедурой библиотеки PLAPACK 3.0 (для
проведения расчетов библиотека PLAPACK использует программную систему MKL
разработки корпорации Интел);
-
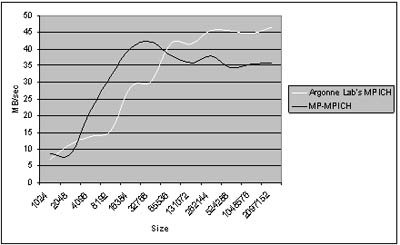 Осуществлен выбор системного
программного обеспечения для организации параллельных вычислений в
многопроцессорных (кластерных) системах; выбранный вариант библиотеки MP-MPICH
обеспечивает более чем на 50% лучшую производительность по сравнению с MPICH,
являющейся одной из наиболее широко применяемых реализаций стандарта MPI;
Осуществлен выбор системного
программного обеспечения для организации параллельных вычислений в
многопроцессорных (кластерных) системах; выбранный вариант библиотеки MP-MPICH
обеспечивает более чем на 50% лучшую производительность по сравнению с MPICH,
являющейся одной из наиболее широко применяемых реализаций стандарта MPI;
-
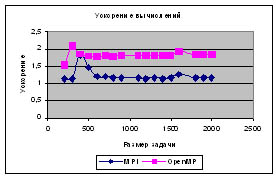
Проведено сравнение эффективности возможных способов разработки
параллельных программ для многопроцессорных вычислительных систем с общей
памятью; результаты выполненных экспериментов показывают, что использование
технологии OpenMP позволяет повысить эффективность параллельных вычислений по
сравнению с применением средств передачи сообщений стандарта MPI (эффект
ускорения может достигать порядка 40%);
-
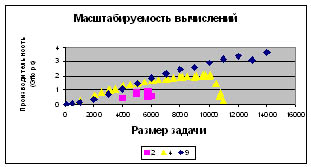 Изучена масштабируемость
(изменение производительности) вычислений при увеличении количества
процессоров вычислительной системы для широко применяемой в практических
приложениях библиотеки параллельных методов PLAPACK 3.0; эксперименты
показали, что увеличению числа процессоров соответствует практически линейный
рост производительности вычислений (для задач матричного умножения и решения
систем линейных уравнений);
Изучена масштабируемость
(изменение производительности) вычислений при увеличении количества
процессоров вычислительной системы для широко применяемой в практических
приложениях библиотеки параллельных методов PLAPACK 3.0; эксперименты
показали, что увеличению числа процессоров соответствует практически линейный
рост производительности вычислений (для задач матричного умножения и решения
систем линейных уравнений);
-
 Проанализирована эффективность вычислений при использовании разных
параллельных методов для решения одной и той же задачи; на примере задачи
матричного умножения проведено сравнение блочных методов Фокса и Кеннона и
алгоритма с ленточной схемой разделения данных; результаты экспериментов
показали, что при относительно малых размерах решаемой задачи лучшую
эффективность имеет ленточный алгоритм; для матриц более высокого порядка
более предпочтительными являются алгоритмы Фокса и Кеннона (различие
эффективности может достигать более 200%);
Проанализирована эффективность вычислений при использовании разных
параллельных методов для решения одной и той же задачи; на примере задачи
матричного умножения проведено сравнение блочных методов Фокса и Кеннона и
алгоритма с ленточной схемой разделения данных; результаты экспериментов
показали, что при относительно малых размерах решаемой задачи лучшую
эффективность имеет ленточный алгоритм; для матриц более высокого порядка
более предпочтительными являются алгоритмы Фокса и Кеннона (различие
эффективности может достигать более 200%);
Сформулирована технология
комбинированной разработки параллельных программ, при которой для организации
взаимодействия между узлами вычислительной системы используются средства MPI,
а для обеспечения эффективных вычислений в пределах отдельных
многопроцессорных узлов с общей памятью применяется способ распараллеливания
на основе OpenMP.
По результатам выполнения проекта подготовлено и опубликовано
учебно-методическое пособие Гергель В.П. и Стронгин Р.Г. "Основы параллельных
вычислений для многопроцессорных вычислительных систем". – Н.Новгород: ННГУ,
2001.
Результаты проекта были представлены на Международных научных
конференциях "Математическое моделирование" (Самара, 2001) и "Телематика 2001"
(Санкт-Петербург,- 2001).




